
A High-Volume ETL Pipeline for U.S. Voter and Address-Change Data
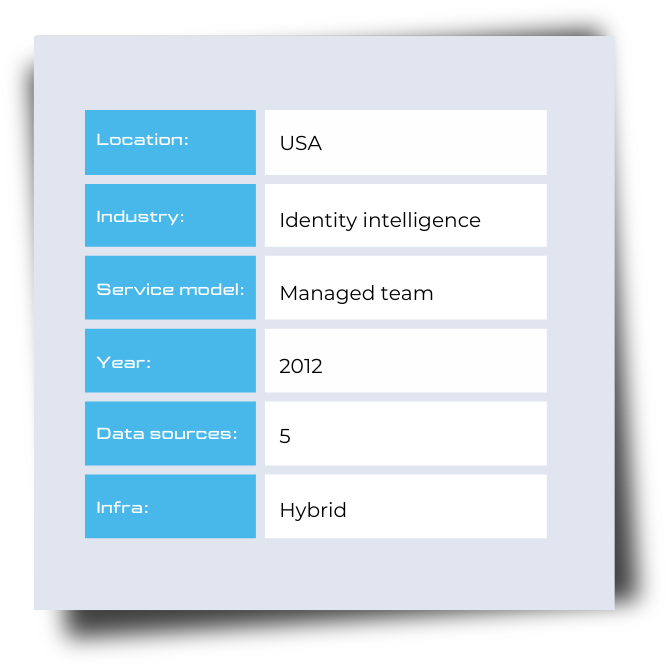
The client is a U.S.-based identity intelligence company that aggregates large volumes of public data for enterprise use cases. Their platform already processed massive datasets, but several high-value voter and mover data sources were not part of the core pipeline.
The client’s goal was to bring these datasets into the main pipeline.
Client expectations:
- Integrate voter and address-change data from 5 external sources into the existing pipeline
- Process and standardize billions of records with inconsistent formats
- Eliminate duplicate and conflicting records across sources
- Build a robust search backend capable of handling extreme data volume
Why This Was Hard
Extreme data volume
The project required processing over 4 billion records collected across multiple external databases. At the time, available infrastructure had strict limits on memory, storage, and compute capacity, making large-scale data operations slow, fragile, and costly.
Fragmented sources
Data arrived from five sources, each with its own structure, field naming, update logic, and data quality issues. The same individuals appeared across multiple datasets, often with conflicting or partially overlapping attributes.
Early-stage tooling
The project was built when big data tooling and distributed processing frameworks were still maturing. Many processes that are automated today require custom engineering, manual optimization, and careful orchestration to remain stable.
Infrastructure limits
Hardware was expensive and constrained. Scaling by simply adding resources was not an option, so the system had to be designed to make maximum use of limited storage, memory, and processing power without sacrificing reliability.
Here Is What We Delivered

The solution was designed as a multi-stage data pipeline that separated ingestion, processing, and search. Data flowed from external sources through a controlled ETL layer, was standardized and validated, and then indexed into a centralized search backend.
Each stage was isolated to reduce failure impact and allow partial reprocessing when needed.

Data was collected from five independent voter and mover sources, each using different formats, schemas, and update logic. During ingestion, records were parsed.
Names, addresses, and core identity attributes were standardized to ensure consistency across sources before further processing.

Before indexing, the system applied identity resolution to detect overlapping records representing the same individual across multiple datasets.
Conflicting or redundant entries were resolved to prevent data inflation and inconsistent search results. Only cleaned and validated records were sent to the SOLR-based search layer for indexing and retrieval.

The system was built under strict infrastructure limits. Hardware was costly, memory was constrained, and distributed data tooling was still evolving.
Because horizontal scaling was not trivial, the architecture favored batch processing, careful resource management, and predictable workloads, prioritizing stability and data integrity over aggressive performance optimization.
Tech Stack for This Project
WPF WCF .NET SQL Server AWS Hadoop SOLR
Results of This Project
Previously isolated voter and mover datasets were successfully integrated into the existing data pipeline and became usable at scale. The client gained a standardized, searchable data layer that could support identity enrichment within their platform.
Key results:
- Integrated five external voter and address-change data sources into the core pipeline
- Built a unified dataset suitable for large-scale identity search and enrichment
- Eliminated duplicate and conflicting records across overlapping sources
- Delivered a stable SOLR-based search backend for downstream systems
- Enabled long-term reuse of standardized data without repeated reprocessing
