
Building the Data Layer for an AI-Powered Vehicle Parts Platform
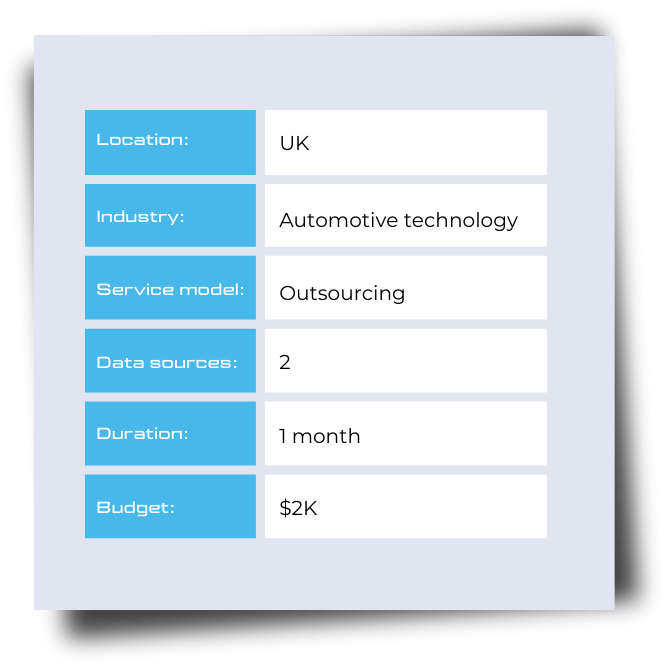
The client is an AI-driven automotive tech company building a vehicle parts procurement platform. Their product helps businesses source genuine spare parts by aggregating catalog data from multiple manufacturers and suppliers.
To make this possible, they needed structured data ingestion from large public automotive parts catalogs.
They approached us with the expectation to:
- Extract automotive parts data from multiple public sources
- Group outputs by manufacturer
- Support European market filtering (e.g., right-hand drive models)
- Handle large-scale extraction under strict onboarding deadlines and budget constraints
Why That Was Hard
Multi-Level Catalog Structure
Each website had deep hierarchies — manufacturer → model → frame → category → subcategory → part → detail. Extracting complete datasets required navigating multiple layers while preserving relationships between vehicles and compatible parts.
Massive Request Volume
Some sources required hundreds of API calls per vehicle model. When multiplied across tens of thousands of vehicles, total request volume exceeded 60 million calls. Estimating infrastructure load, execution time, and cost became a critical engineering task.
Dynamic API Protection
One major source relied on token-based authentication and session control. Standard scraping logic stopped working after protection updates. We had to simulate real browser behavior and manage rotating tokens to maintain stable and uninterrupted data extraction.
Parallel Deadlines
The platform had strict onboarding dates for its first customers. Data had to be ingested, cleaned, and delivered ahead of those milestones. We needed to balance testing, stabilization, and speed without risking blocks or failed large-scale runs.
Here Is What We Delivered

After gathering requirements, we built a free loading module and delivered a sample dataset from one source. This allowed the client to validate data format, field consistency, grouping logic, and overall usability before committing to full-scale extraction.
At the same time, we provided record counts within scope, estimated timelines, budget calculations based on projected volume, and an execution plan.
Only after alignment did we move forward with a formal agreement and full delivery.

The project expanded from one website to multiple large automotive catalog sources. Each required different filters — manufacturer, region, production years, and “Genuine Parts” only.
We handled data extraction from multiple catalog platforms, filtering by European models where required, limiting scope to recent model years, and prioritizing selected brands to meet deadlines and budget constraints.
As the client refined priorities, we adjusted the scope and recalculated volumes.

Data was delivered in formats aligned with the client’s ingestion pipelines.
We provided structured JSON exports, chunked files for easier processing, and direct uploads into the client’s S3 environment.
This allowed their engineering team to start building internal pipelines immediately, without additional transformation work.
Results of the Project
We enabled the client to build their automotive procurement platform with structured, production-ready catalog data.
Through a phased approach — including free module development, sample validation, and continuous scope refinement — the client gained clarity on cost, timelines, and technical feasibility before scaling.
Key Results:
- Delivered validated sample datasets before contract signing
- Adjusted scope dynamically to control infrastructure expenses
- Enabled phased rollout aligned with platform onboarding deadlines
- Preserved reusable modules for future activation
- Loaded 313K+ automotive parts records into the platform
